
Cloud-native hybrid transactional and analytical processing with Cosmos DB and Azure Synapse
Hybrid transaction analytical processing is a term created by Gartner. As defined by Gartner:
Hybrid transaction analytical processing (HTAP) is an emerging application architecture that breaks the wall between transaction processing and analytics. It enables more informed and “in business real time” decision making.
Hybrid transaction analytical processing refers to capabilities to perform online analytical processing (OLAP) and online transaction processing (OLTP) at the same time on the same database system. Typically we need to build and manage an ETL pipeline to get data from the operational store over into the analytical store. To minimize interference and keep costs down, we try to schedule this during off-peak hours.
That means your data is going to be unpredictably out of lag with the source.
1. Introduction
Azure Synapse Analytics is an integrated analytics service that accelerates time to insight across data warehouses and big data systems at massive scale. It brings together the best of SQL technologies for enterprise data warehousing; Apache Spark technologies for big data; and pipelines for data integration and extract, load, transform (ELT).
Azure Synapse Link for Azure Cosmos DB is a cloud-native hybrid transactional and analytical processing capability that enables us to run near real-time analytics over operational data in Azure Cosmos DB with no ETL and no performance impact to mission-critical transactional workloads.
We take the operational data we want to analyze and automatically maintain an analytics-oriented columnar version of it. Any changes to the operational data in CosmosDB are continuously updated to your linked data and Synapse.
Advantages:
- much simpler to perform continuous live analytics
- more performant
- cheaper
- no pipelines to manage between the transactional data and analytics data
The image below gives an overview of what we will implement today.
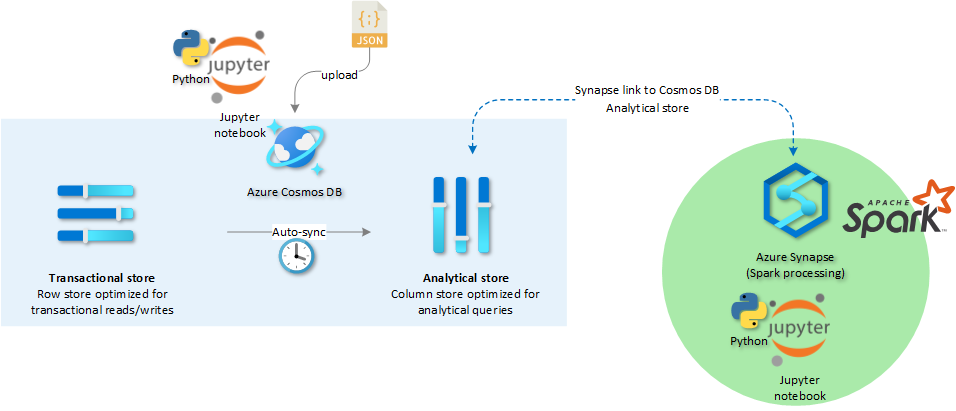
2. Setup transactional store
After deploying an empty Cosmos DB account, the first step we take is importing our Azure Cosmos DB Jupyter notebook.
![]()
Jupyter Notebooks are best known as tools for Data Scientists to display Python, Spark or R scripts. A Jupyter Notebook enables you to share words, images, code AND code results. Notebooks democratize access to data and the understanding of data. The successful analysis of data is at the heart of success for a lot of enterprises. They unlock the potential of the technology that we have and put it in the hands of a much wider range of people.
You can find back the Jupyter notebook we use for Cosmos DB cosmosdb.ipynb in the repository (see link at end of the blog post). Click on Notebooks > Upload File.
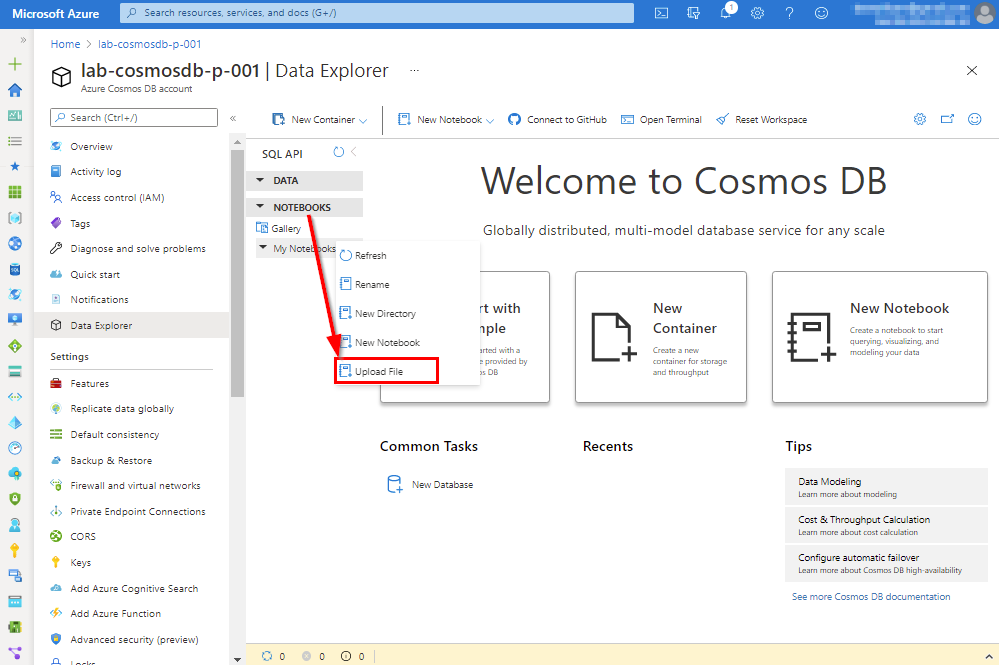
2.1 Create Cosmos DB database
Once the Notebook is visible, we can easily walk through the code blocks. Press the play button in de code cell to execute the commands. The output can be viewed directly.
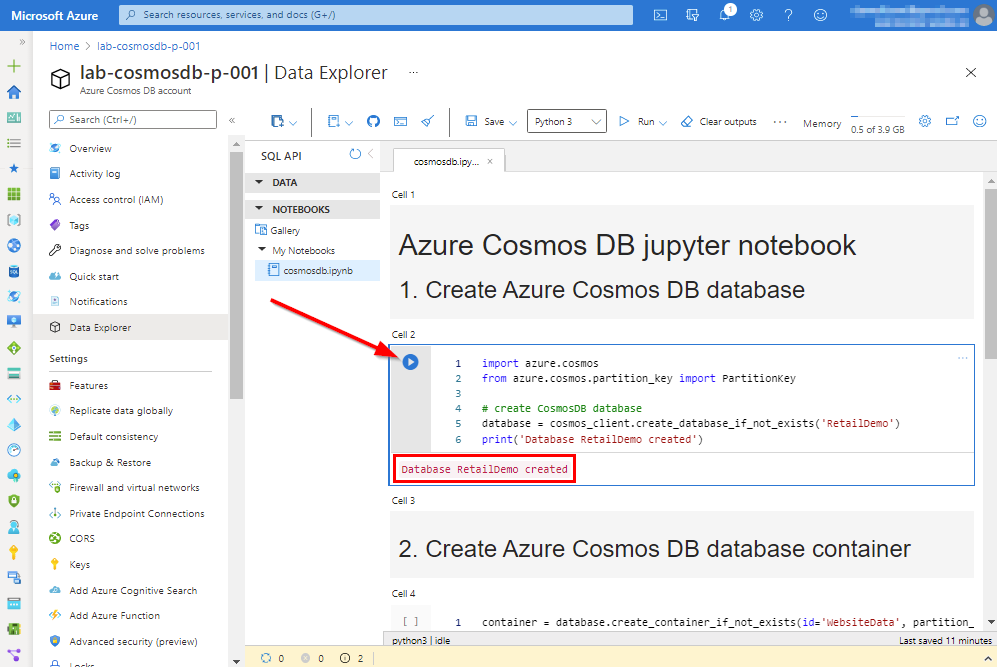
2.2 Upload JSON data
By default not every container will have an analytical store enabled. This setting needs to be set explicitly (analytical_storage_ttl=-1) at creation time. In step 3 we are oging to upload data in our Cosmos DB container. Again the output is displayed together with the amount of Cosmos DB request units consumed for this operation.

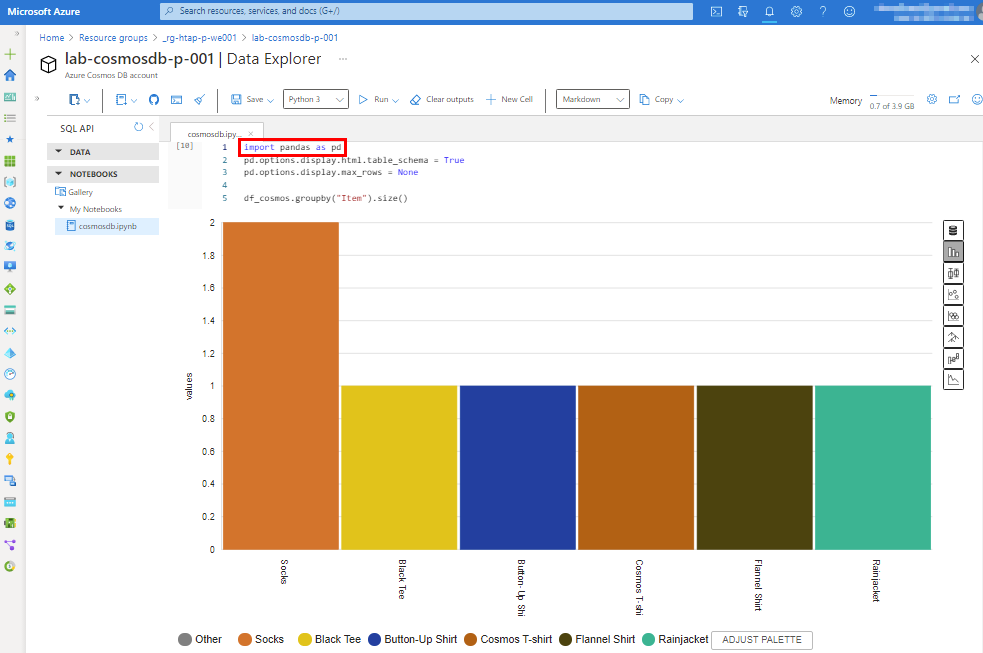
Within the Jupyter notebook, we can import the Python Panda library used for manipulating data and loading data into a pandas Dataframe. It allows us to visualize data that renders a data set as a graphic.
3. Setup cloud-native HTAP
When our Azure Synapse workspace is deployed, we first need to link to our existing Azure Cosmos DB Account.
Open the Azure Synapse workspace and go to Linked services in the Manage menu > + New.
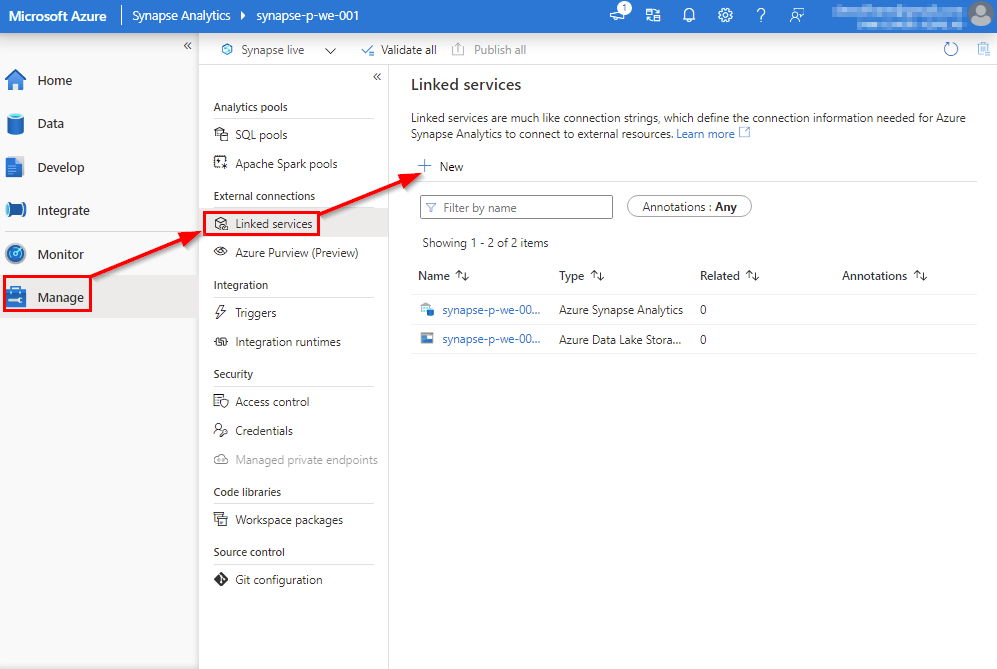
Our operational data is stored in a Cosmos DB Account.
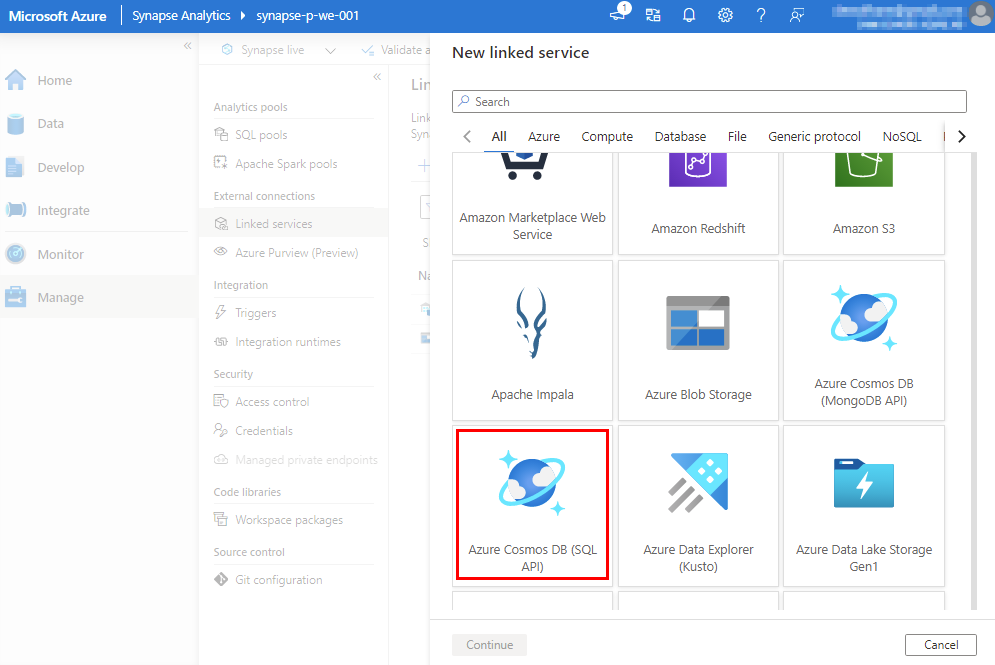
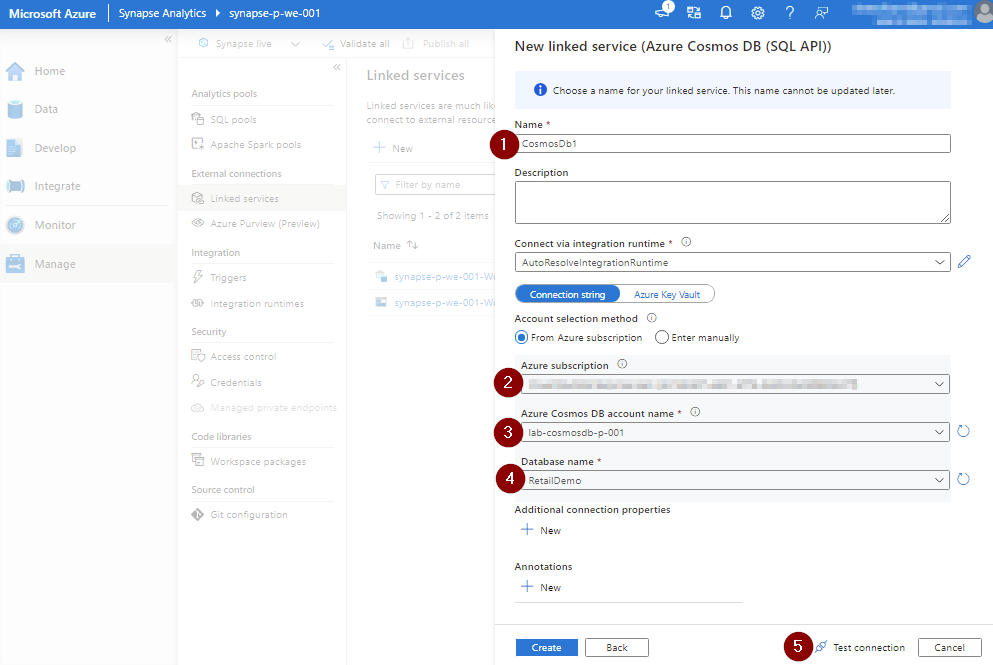
Select your Azure subscription, Cosmos DB Account and Database name.
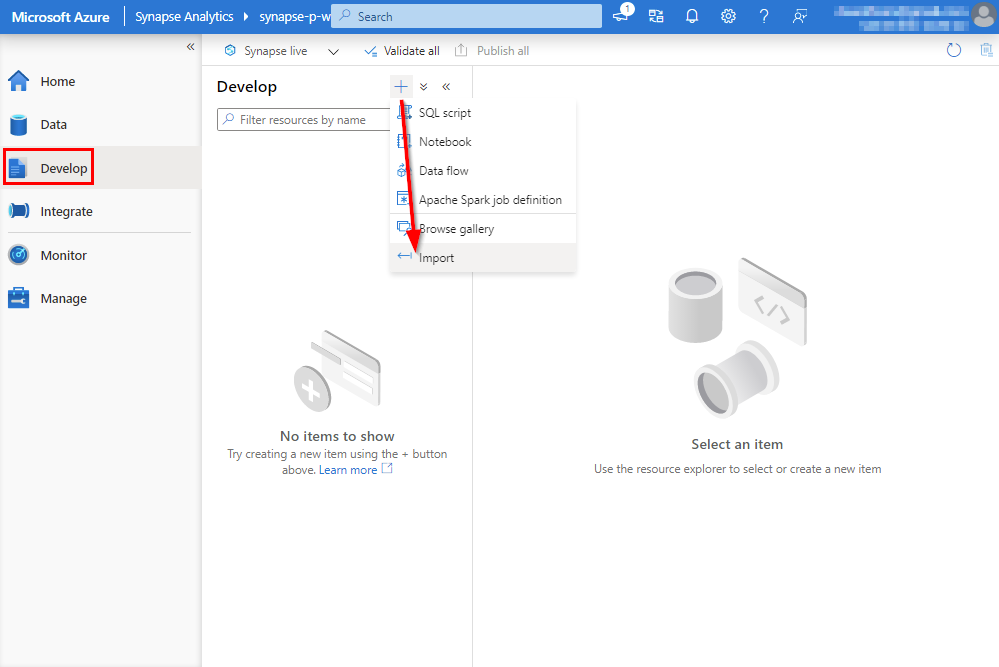
3.1 Synapse Notebook
Also in Azure Synapse, we make use of Jupyter notebooks. From the Develop menu in the workspace we can import the notebook. You can find back the Azure Synapse Jupyter notebook file synapse.ipynb in the repository (see link at end of the blog post).
3.2 Interact with Azure Cosmos DB using Apache Spark in Azure Synapse
Press the play button in de code cell to execute the commands. The output of the Spark job can be seen inside the Jupyter notebook.
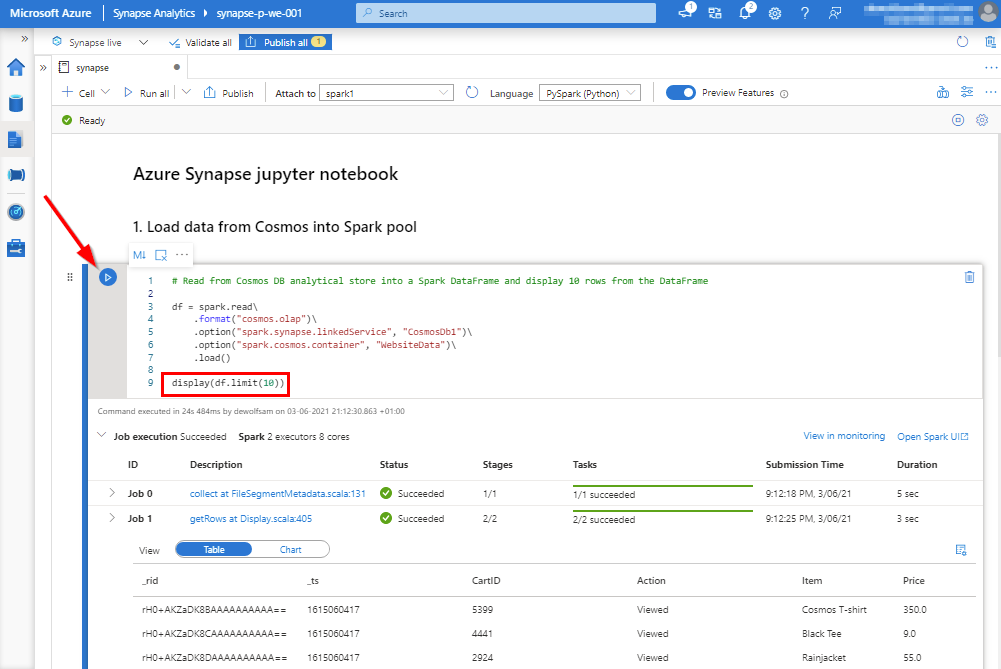
- line 3: define read data imported to DBFS into Apache Spark DataFrame
- line 4: read data from Azure Cosmos DB using the OLAP storage driver to avoid consuming throughput request units on a Spark cluster
- line 5: reference the linked service to our Cosmos DB account
- line 6: refererce the Cosmos DB container
- line 9: display the first 10 results
When the data is stored in the dataframe, we import the Spark SQL classes so that we can create an aggregate of the Price column.
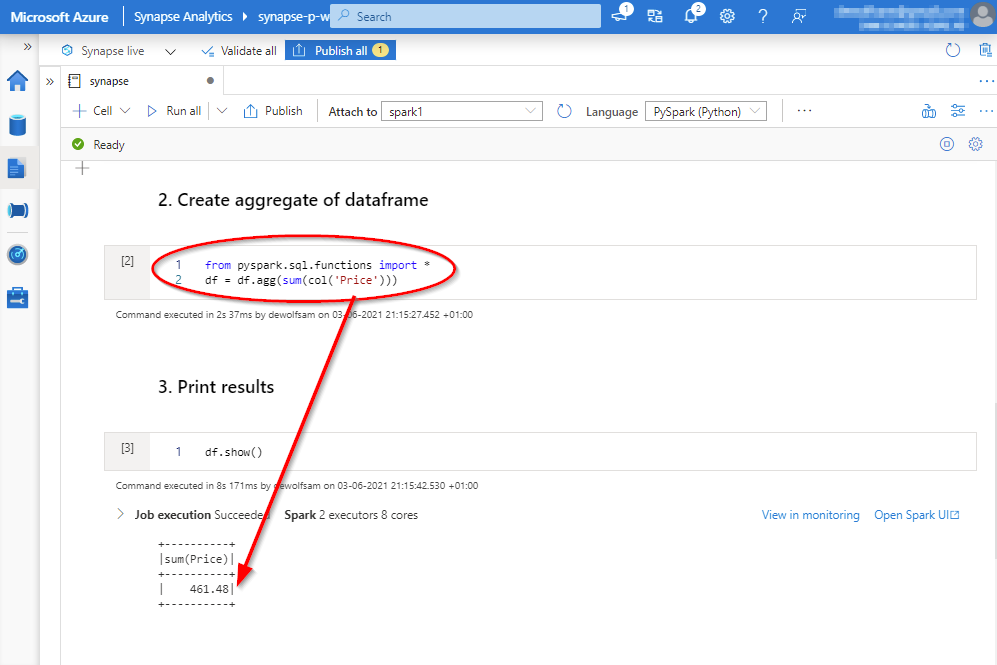
When new data is inserted into the Cosmos DB container, after a few moments, we will be able to use this data in Azure Synapse with the Spark cluster for analytic purposes without any extra interventions.
The configuration we used in this post can be found on https://GitHub.com/dewolfs/cosmosdb-synapse-htap.